SQL Server documentation
Basic SQL documentation
Basic query
1SELECT * FROM mytable
Joining tables
Here is a graphical visualization of the different JOIN operations:
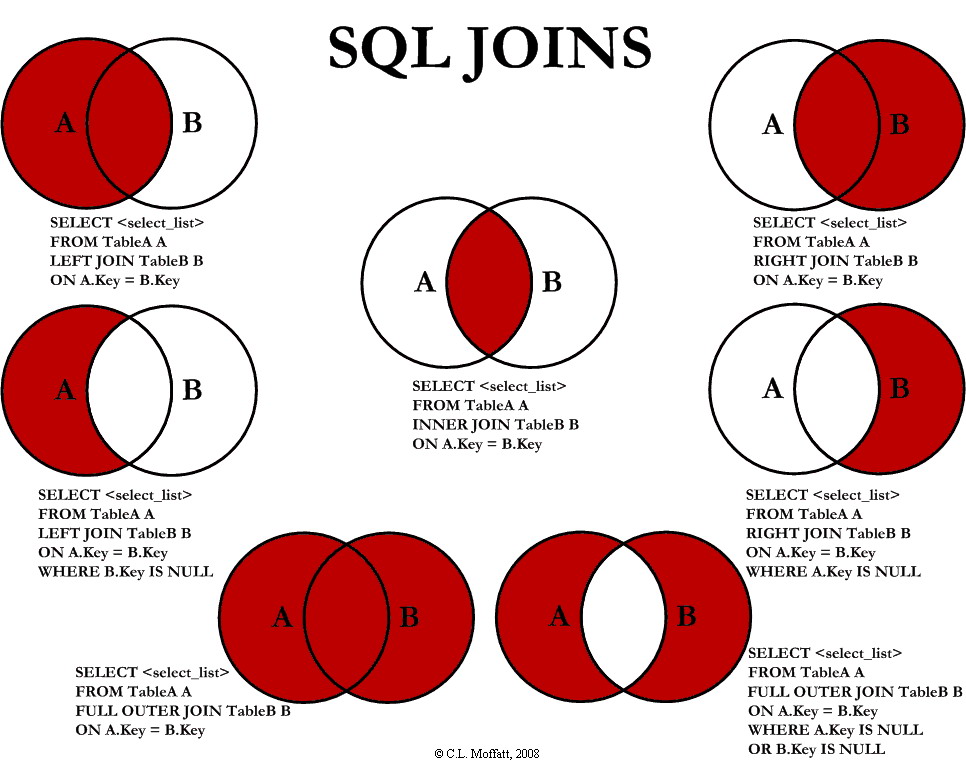
Taken from https://www.codeproject.com/Articles/33052/Visual-Representation-of-SQL-Joins
Keys in SQL
A primary key uniquely identifies a row.
A composite key is a key formed from multiple columns.
A partition key is the primary lookup to find a set of rows, i.e. a partition.
A clustering key is the part of the primary key that isn’t the partition key (and defines the ordering within a partition).
(is this specific to Cassandra, or valid for SQL in general?)
Examples:
PRIMARY KEY (a): The partition key is a.
PRIMARY KEY (a, b): The partition key is a, the clustering key is b.
PRIMARY KEY ((a, b)): The composite partition key is (a, b).
PRIMARY KEY (a, b, c): The partition key is a, the composite clustering key is (b, c).
PRIMARY KEY ((a, b), c): The composite partition key is (a, b), the clustering key is c.
PRIMARY KEY ((a, b), c, d): The composite partition key is (a, b), the composite clustering key is (c, d).
Import data from another server
In some cases, data needs to be imported from another server. For that OPENROWSET is useful:
1SELECT *
2INTO ETZ33839AA.dbo.HNWI_userlist
3FROM OPENROWSET(
4 'SQLNCLI', 'Server=CF4S01\INST001;Trusted_Connection=yes;',
5 'Select *
6 FROM [MCS_ModelDev_Score].[DK_PRV_2016].[test_pbe_pf_for_bda]'
7)
Other example, with condition:
1SELECT *
2INTO [ETZ3BSC1].[NT0001\BC1733].[SME_OOT_FINNISH_CUSTOMERS]
3FROM OPENROWSET(
4 'SQLNCLI', 'Server=CF4S01\INST001 ;Trusted_Connection=yes;',
5 'SELECT le_unit_master, run_ts
6 FROM [MCS_ModelDev_Score].[GSM_Comp].[DEV_VAL_201511_0040_V2]
7 WHERE R_NEW_B_TYPE = ''B_SC_13''
8'
9)
Rank function - Exercise

1--First: join on knid, build difference SCOREDATE-CREATIONDATE
2select a.KNID,a.CREATIONDATE,b.SCOREDATE,b.SCORE, datediff(day,b.SCOREDATE,a.CREATIONDATE) as DateDifference
3into #temp
4from #t1 as a
5join #t2 as b on a.KNID = b.KNID
6where datediff(day,b.SCOREDATE,a.CREATIONDATE) > 0
7
8--Second: in DateDifference, the smallest positive value is the one we need. So we build a Rank on that,
9-- for each KNID--CREATIONDATE group (see the partition by clause)
10select KNID,CREATIONDATE,SCOREDATE,SCORE,DateDifference
11,RANK() OVER
12 (PARTITION BY KNID,CREATIONDATE ORDER BY DateDifference ASC) AS Rank
13into #temp2
14from #temp
15
16--Third: we select Rank=1 to get the SCOREDATE AND SCORE for each KNID--CREATIONDATE combination
17select * from #temp2
18where Rank = 1
19order by CREATIONDATE desc
20
21select * from #result
22order by CREATIONDATE desc

Joining on KNID and earlier than some dates
We sometimes need to join data on KNID and on some date…but not exactly the same date, but table2.date <= table1.date… Seems tricky to do! Here is a way to do that:
1SELECT ID, Date, Price
2FROM (
3SELECT B.ID, B.Date, B.Price, ROW_NUMBER() OVER (PARTITION BY A.ID ORDER BY ABS(DATEDIFF(Day, A.Date, B.Date))) AS SEQ
4FROM TableA AS A JOIN TableB AS B
5ON A.ID=B.ID
6WHERE B.Date<=A.Date ) AS T
7WHERE SEQ=1
Posgresql
How to install client and server on Ubuntu 20.04: https://linuxconfig.org/ubuntu-20-04-postgresql-installation, https://www.digitalocean.com/community/tutorials/how-to-install-and-use-postgresql-on-ubuntu-18-04
How to create user, db, create tables: https://www.digitalocean.com/community/tutorials/how-to-create-remove-manage-tables-in-postgresql-on-a-cloud-server